Problem 1 to Fix 1
Changing one heading required downloading and reuploading the entire page.
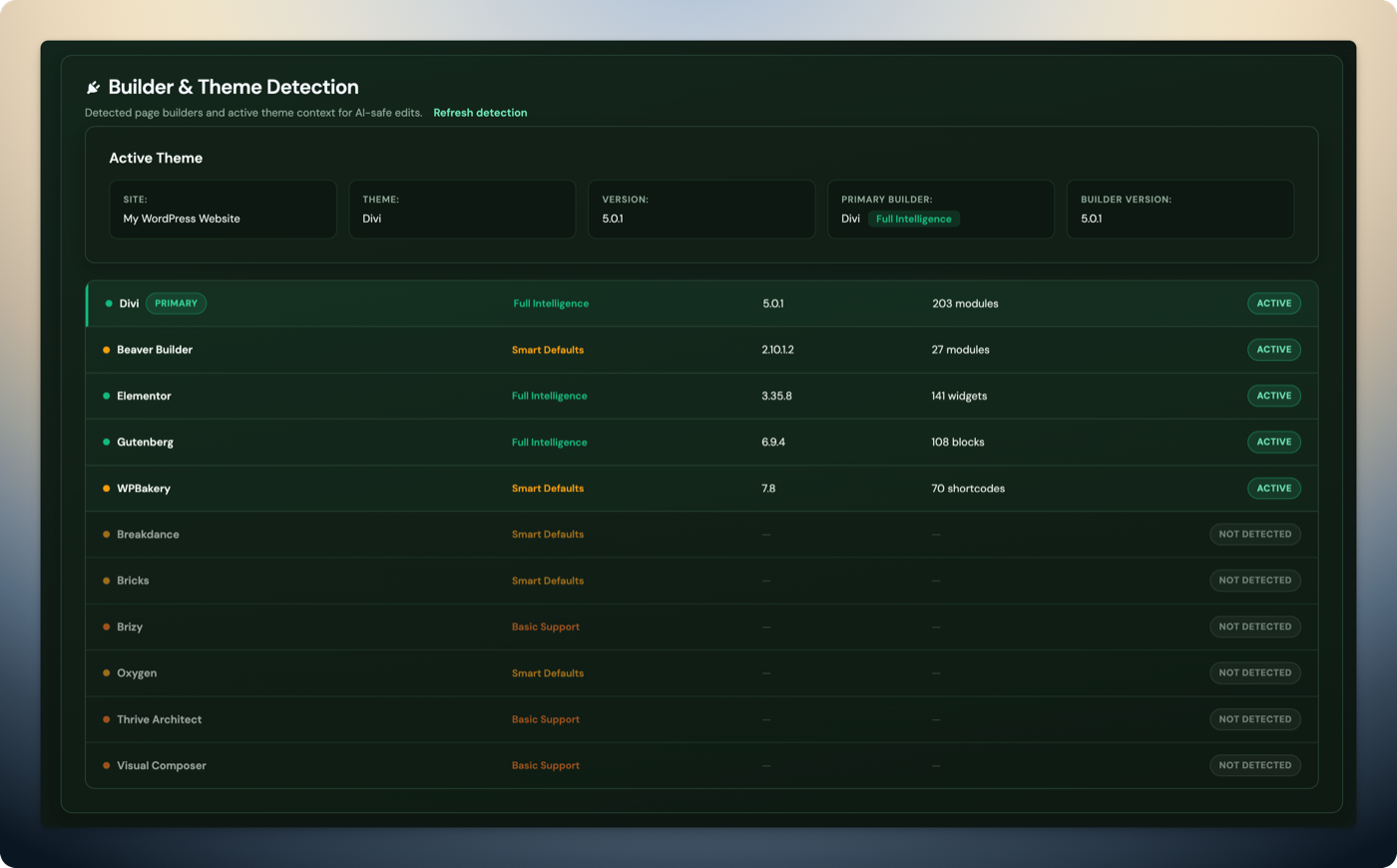
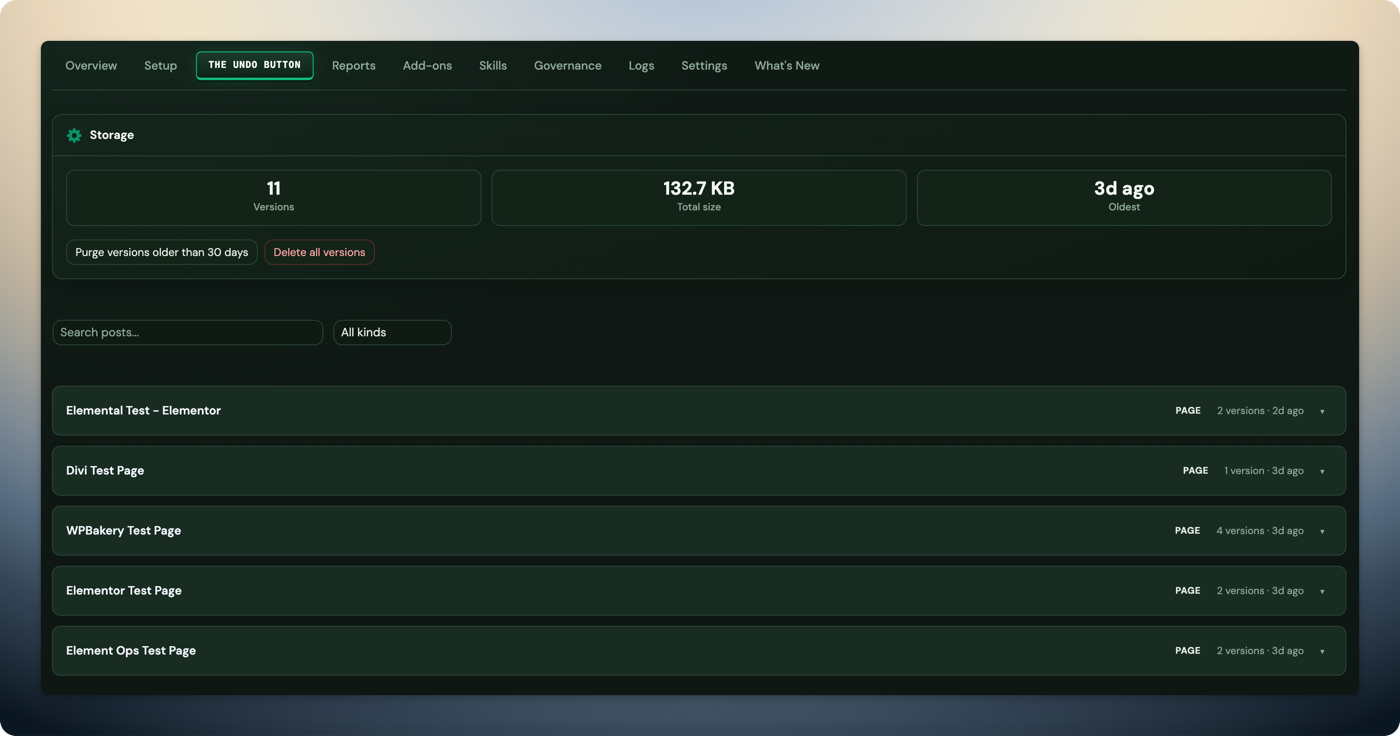
Every MCP edit — even changing a single word in a heading — required downloading the full page structure, parsing it, making the change, and uploading it all back. For a page with 200 Elementor widgets, that is thousands of tokens round-tripped for a one-line change.
-
What the user experienced
Slow edits, high token consumption, and occasional data corruption when the full-page round-trip hit a conflict or timeout.
-
Why it happened
The only edit path was read_page → modify in memory → update_page. No way to target a specific element without moving the entire page structure.
-
What we shipped
Five element-level operations: find_element (search by ID, type, class, or content), update_element, move_element, duplicate_element, remove_element. The page stays on the server. Only the targeted element moves over the wire.
-
Benefit
~50 tokens for a heading change instead of ~5,000. Faster edits, lower cost, zero risk of collateral damage to other elements on the page.
Edit approach comparison
Changing a heading: full-page vs element-level
Download 200 widgets, all settings, all structure
Find the widget, change the text
Upload entire page back with one changed heading
~8,200 tokens, 3 API calls, full page at risk of corruption during write-back.
Target the heading widget directly, change only the text
~50 tokens, 1 API call, only the heading widget is touched. Everything else stays exactly as it was.